2019 - Raspberry PI AI
- 🚀 GitHub repo with code and dataset.
- 🎙 Conference talk from this project.
- 📖 Talk slides.
- 🐰 My blog post on Deep Learning fundamentals.
In spring 2019, I was working in an office next the Amsterdam airport, and I could see lots of planes passing by, very close. Such view never stopped exciting me, so the idea: write from scratch and train a deep learning network to alert me when there is a plane passing by.


The little PI would take pictures that looked like the below examples. For the purposes of this project, these images belong to two classes:
- There is a plane on the bridge. Or,
- No plane is on the bridge.


The actions for this project are:
- Implement a binary classifier Convolutional Neural Network.
- Deploy it on the Raspberry PI and Build the entire pipeline (take pictures, classify them, tweet them…)
- Evaluate the performance of the network and improve it.
Implement a binary classifier
The network I chose to build is a Convolutional Neural Network, starting from a classic LeNet model and tweaking for my own case. I tried both the TensorFlow Java API and Deeplearning4j. I liked the latter a lot more as the JVM is the primary target; TensorFlow felt too ‘phyton-esque’.
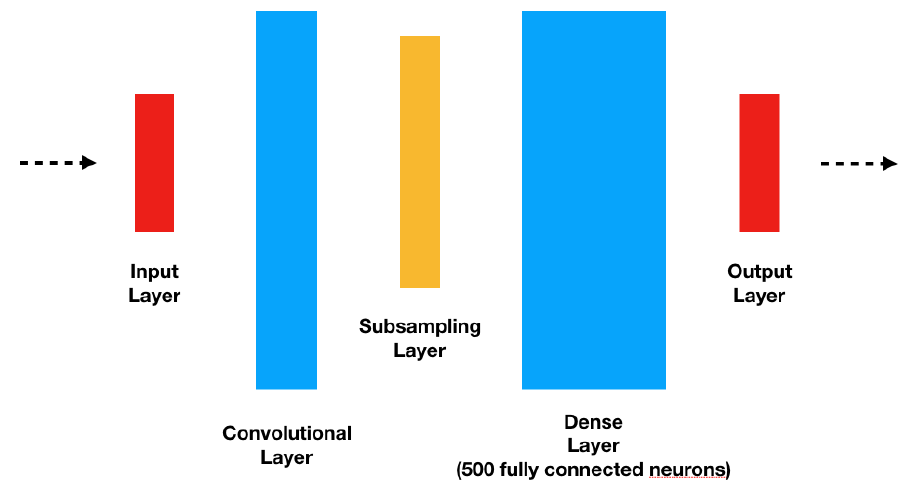
All relevant code can be found in the GitHub repo. The following snippet is the part where I bring together all the layers of the neural network.
// creates the actual neural network
def getNetworkConfiguration: MultiLayerConfiguration = {
new NeuralNetConfiguration.Builder()
.seed(seed)
.l2(0.0005)
.weightInit(WeightInit.XAVIER)
.updater(new Adam(1e-3))
.list
.layer(0, new ConvolutionLayer.Builder(5, 5)
.nIn(depth) // nIn and nOut specify depth. nIn here is the nChannels and nOut is the number of filters to be applied
.stride(1, 1)
.nOut(20)
.activation(Activation.IDENTITY)
.build)
.layer(1, new SubsamplingLayer.Builder(PoolingType.MAX)
.kernelSize(2, 2)
.stride(2, 2)
.build)
.layer(2, new ConvolutionLayer.Builder(5, 5)
.stride(1, 1) // Note that nIn need not be specified in later layers
.nOut(50)
.activation(Activation.IDENTITY)
.build)
.layer(3, new SubsamplingLayer.Builder(PoolingType.MAX)
.kernelSize(2, 2)
.stride(2, 2)
.build)
.layer(4, new DenseLayer.Builder()
.activation(Activation.RELU)
.nOut(500)
.build)
.layer(5, new OutputLayer.Builder(LossFunctions.LossFunction.MCXENT) // to be used with Softmax
.nOut(numClasses)
.activation(Activation.SOFTMAX) // because I have two classes: plane or no-plane
.build)
.setInputType(InputType.convolutional(outputHeight, outputWidth, depth))
.build
}Build the pipeline
I used Akka Streams to bring everything together in a powerful and elegant way.
The largely untold truth is that the strictly AI parts of AI projects are just a tiny part of it. So much work goes into the many IO operations, take an image, resize it, copy it around, classify it, tweet it… All of these operations take time and can fail.
This is a diagram where the three most important flows are represented. The only blocks about AI are the blue ones.
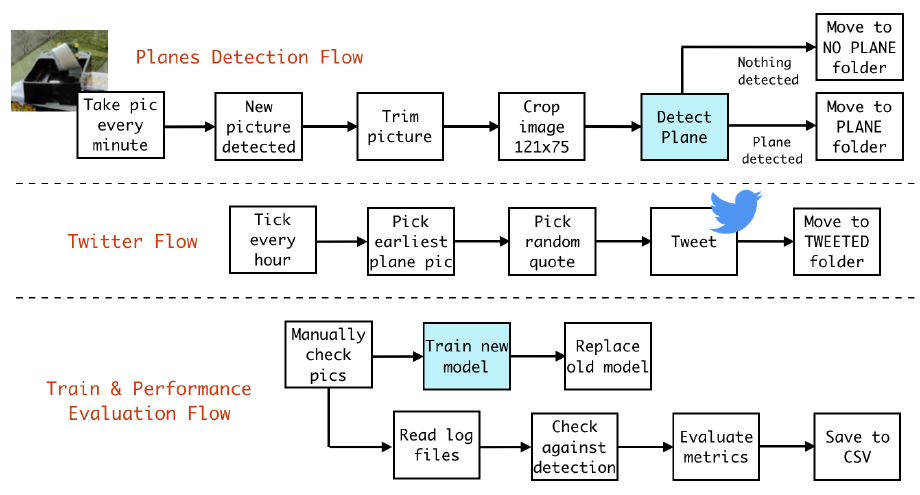
I cannot stress enough how powerful Akka Streams is. Typed, composable, integrations for any machinery piece you might need (FTP? Kafka? TCP? File operations?) and just so much fun to use.
Training the network requires a dataset first. In my case, this meant collecting about 16.000 images, look at each one of them and label it: ‘PLANE’ or ‘NOPLANE’. A painstaking work that should discourage anyone to follow steps, but at the same crucial for humanity as we’ll see shortly.
Evaluate the performance of the network
During the training phase, at each training epoch your trainer will use the test images to see how the network performs against them. That is the first indication of your model’s capabilities. The real world is another thing though.
If you want to evaluate your network performance in the open field, you need to save the original image together with the network’s prediction. Only then you can look at the image and see if the AI got it right. It’s more painstaking work, but at least it comes with the benefit that you can use the human-validated images to enrich your dataset and train your model again.
The most important parameters I looked at where the Precision and the Recall, both measures between 0.0 and 1.0.
- Precision: shows how well the model avoids false positives.
- Recall: shows how well our model avoids false negatives.
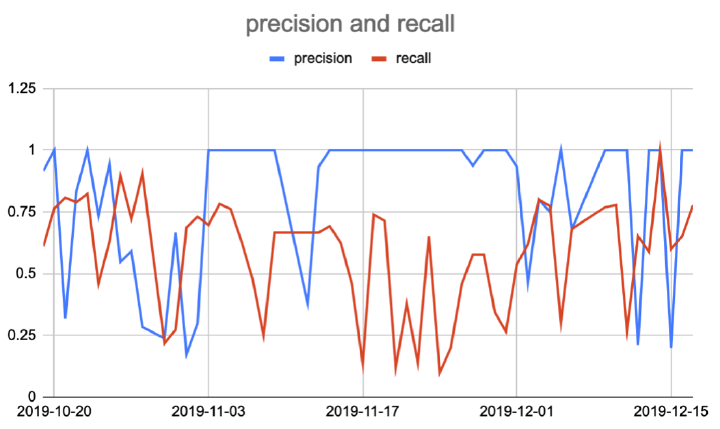
The image above tells us that while the Precision is very high (some days even 1.0), the Recall is overall not that great.
Few false positives mean that when the network believes that there is a plane in the picture, usually there is one. At the same time, there are a lot of false negatives: there was a plane, but the network didn’t see it.
Which is fine: in fact, the network’s behaviour is always a compromise. In my case, I am happy with having few false positives and many false negatives, because what I care about is that the tweeted images do contain a plane. Not a big deal if the network misses some planes. Different cases will call for a different compromise.
The image below show common cases where the network uncorrectly declares that there is no plane: the different weather conditions confuse the network greatly, but also cases where a plane is only partially visible.

Bonus: AI Bias and what to do about it
There is another important factor behind the fluctuating network performance: AI bias. The network was traine in the Netherlands, where the national air company sports blue planes. So the model grew up heavily skewed towards blue planes.

This shows in the network clearly able to see blue planes much better than other planes.
Even such a playful project like this one turned out to be plagued by AI bias. The only solution to this problem is a balanced and heterogeneous dataset. This is a VERY difficult challenge. It seems clear to me that datasets should be put together by different people (or entities) than those who actually implement the network.
The task of compiling a balanced dataset is incredibly challenging, and we have all seen that the repercussions can be tragic. Think sensible domains like health, or any interaction with human rights in general. Security, job candidate screening and so forth, where racial or gender bias (just to name two) could creep in at any point.
The only solution is tasking the right people with assembling a dataset. In my view, this is one of the most difficult challenges that humanity faces already.
